
종우의 삶 (전체 공개)
그래프 탐색? 그게 어떻게 하는 건데 본문
알고리즘 공부를 시작할 때 들어본 DFS, BFS를 드디어 만났다.
깊이 우선 탐색, 너비 우선 탐색 그래 말은 좋다 이거야
문제를 읽어본 결과 하나도 모르겠다는 것이 나의 결론이었다.
어쨌든 정리를 하면서 살펴보자. 정점과 노드를 혼용하여 사용할것이나 같은 의미로 생각하자.
0. 정점(vertex)과 간선(edge)
우선 말이 어렵다. 정점은 무엇이고 간선은 무엇인가. 코드에 적어야 할 vertex와 edge를 우선 알아야 하겠다.
정점(또는 노드)과 간선은 그래프에서 쓰이는 말이다. 그래프는 정점과 간선으로 이루어져있는 조직도로 생각하면 되는데
정점은 데이터가 저장되는 곳이고, 간선은 그 정점들을 연결하는 선이다.
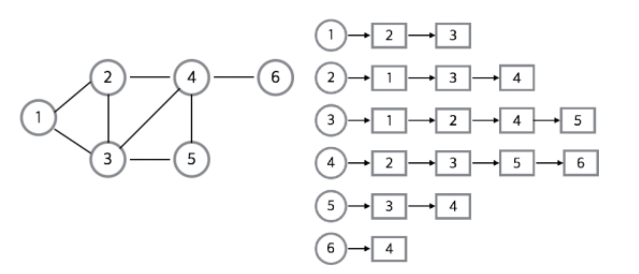
좌측에 있는 그래프를 보면 번호가 들어있는 정점(동그라미)와, 그 정점들을 연결하는 간선들이 보인다.
우측은 저렇게 생긴 그래프를 표현하는 방식인데, 여러가지가 있으므로 구글링을 하세요.
코드를 만들고 문제를 풀기 위해선 저렇게 정리하는 방법이 필요하다. 아래에 비슷한 내용이 등장할 수 있음.
이러한 그래프를 탐색하는 방법이.. DFS와 BFS인 것이다.
1. 깊이 우선 탐색 - DFS
말 그대로 펼쳐진 그래프를 최대한 깊게 내려갔다가 (Depth First) 다시 돌아오는 방법이다. 정확히는 다음 간선으로 넘어가기 전에 해당 간선들을 전부 탐색하는 방법이다.
-> 모든 정점을 방문하고자 하는 경우에 주로 사용한다.
2. 너비 우선 탐색 - BFS
DFS가 세로로 쭉 들어가는 느낌이었다면, BFS는 가로로 읽는다. 시작 정점에 인접한 모든 간선을 탐색하며 인접한 모든 정점를 먼저 탐색한다.
-> 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을때 사용

3. 두 방법을 어떻게 구현할 것인가? (Python)
머리속에서 그래프를 만들고 인접 리스트를 생성하고 자유자재로 바로 위 그림처럼 탐색을 할 수 있다면 얼마나 좋을까?
하지만 그것이 불가능하기에 우리는 여러 단계를 거쳐야한다.
우선 DFS, BFS에도 구현 방법은 여러가지가 있지만, 인접 리스트를 활용한 방법으로 접근해보겠다. 개인적으로 그나마 직관적으로 다가왔다.
DFS부터 예제를 이해해보자.
DFS
# 인접 리스트로 그래프 구현
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
# 깊이 우선 탐색 (DFS) - 재귀적 구현
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
print(start, end=' ')
for next in graph[start]:
if next not in visited:
dfs(graph, next, visited)
print("DFS 탐색 순서:")
dfs(graph, 'A')
탐색을 구현하는 것 이전에 우선 그래프를 코드로 해석하는 과정이 필요하다. 예제에서는 인접 리스트를 딕셔너리 형태로 직접 구현해 놓았다.
(몇개 보지 못한 문제들이지만) 대부분의 문제에서는 그래프를 인접 리스트, 혹은 다른방식으로 구현할 수 있도록 데이터가 주어지기 때문에 문제에서 요구하는 목표를 찾아내기 위해서 데이터를 잘 가공할 수 있어야하겠다.
그래프를 얻었으니, 이제 DFS 함수를 보자
def dfs(idx):
stack = []
# 빈 스택을 생성
stack.append(idx)
# 맨 처음의 값 - 노드를 집어넣음 (idx)
# 이후 pop으로 꺼내면서 방문했는지 로그를 표시할 것임
# 스택이 빌 때까지, while문을 실행할 것이다.
while stack:
current = stack.pop()
print(f"{current} 방문!")
visited[current] = True
for adj in graph[current]:
if not visited[adj]:
stack.append(adj)
visited[adj] = True스택을 사용한 DFS
while 문을 살펴보면,
가장 먼저 들어간 노드의 인덱스 값이 현재 스택에 남아있다.
그것을 pop으로 꺼내면 그 노드의 값을 읽은, 즉 탐색 한 것이 된다.
print로 로그를 확인하기 위해 current = stack.pop()을 출력해준다.
visited 리스트는 인접 리스트와 함께 초기에 생성된것으로 [False] * (node수 +1) 인 False형태로 이루어진 리스트인데,
탐색이 완료된 인덱스의 값을 True로 변경하여 아직 방문하지 않은 곳만 갈 수 있게 조정한다.
graph 리스트 안에 인접 값들이 저장되어있기 때문에,
다음 for 문에서 가장 처음 시작한 current의 인접 값들 adj을 탐색한다.
if not을 이용하여 인접 값들이 아직 false라면 스택에 추가하고, visited값을 True로 바꾼뒤 while의 처음으로 돌아간다.
결국 저장된 그래프의 값을 전부 순회하게 될 것이다. 전부
여기서 인덱스의 0은 사용하지 않기 때문에 ,visited[0]은 그대로 남아있다. 메모리의 낭비가 생긴다.
# 깊이 우선 탐색 (DFS) - 재귀적 구현
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
print(start, end=' ')
for next in graph[start]:
if next not in visited:
dfs(graph, next, visited)DFS는 재귀적으로 구현하거나 스택을 이용하여 구현할 수 있다.
재귀적으로 접근하는 것도 결과적으로는 스택의 방식과 같다.
집중력이 심히 떨어져 2편에 계속..
BFS는 그때 다뤄보자.
'일지 > 코딩 테스트 , Algorithm' 카테고리의 다른 글
| 소수 스페셜 - 에라토스테네스의 체 (0) | 2024.06.17 |
|---|---|
| 2분 안에 알아보는 이진 탐색 (Binary Search) (1) | 2024.06.08 |
| 시간복잡도와 함께 올라가는 내 정신복잡도 (1) | 2024.06.07 |
| 힙하지 않은 힙 (0) | 2024.06.06 |
| 큐는 어렵다. 큐는 모르겠다. 큐큐큐;;; (0) | 2024.06.05 |

